
Recently I have been learning a (little) bit of Python in my spare time in the hope that it will help me become better at SEO. And finally, I have created my first script, with the aim of finding internal linking opportunities at a large scale.
Interested in learning Python? Try this resource:
[do_widget id=custom_html-3]
Goal
This script is specifically designed to be used when an ecommerce site has a blog. Ideally, every time the blog mentions a keyword, it should link to the relevant category or product in the store. For example, if you’re a bed retailer and you mention the term [double memory foam mattress] within the blog, it should link to the ‘Double Memory Foam Mattress’ category. A similar method can be found here.
However, blogs are often written by those who do not specialise in SEO and therefore miss opportunities to link to important pages. We want to highlight every instance of a keyword where the article does not link to the landing page. Doing this for individual keywords is fairly straight forward, but doing it for 100s or 1000s of keywords across 100s of blog articles isn’t feasible. Therefore, we need a script to do all the hard work for us.
Whilst I designed this script to find opportunities in the blog, it will also work with category and product descriptions to ensure that internal linking is solid throughout the site.
Preparation
For this task, you will need the following
- Install Python
- An up to date keyword map
- Screaming Frog
- Basic knowledge of custom extractions
Once Python is installed on your computer and you have completed your keyword research, the next step is to crawl the content of your blog so that all the articles can be saved into a single CSV file. This can be done using custom extractions.
If you’re unsure how to proceed, why not read our guide on how to use Xpath for custom extractions.
For this script, we are only interested in the article content so we want to strip out navigation and footer links. Most blog themes contain the copy within a single HTML element, such as <div class=”content”>. For this example, we would want to create a custom extraction for the Xpath //div[@class=’content’]. Once you have got this figured out, run your crawl and export you extractions as a CSV.
You will need to open your CSV file using Excel to make sure that there are no formatting issues. Sometimes special characters within an article will mess up the CSV so you may need to give it some tweaking.
Once your CSV is ready, format it into 2 columns – the 1st being the articlee URL and the 2nd is the content, and save as blog-list.csv. Then save your keyword list as kw-list.csv, with your target URLs in the 1st column and the mapped keywords in the 2nd. See images below for examples or click here to download our sample CSVs. Both files should be saved in the same folder as your Python script.
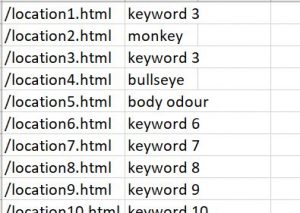

This might all sound a bit complicated, but it really isn’t. Just follow the templates provided and it should be fine.
Process
The script itself is really simple, and mainly consists of a FOR loop within a FOR loop. See the flow chart to see how it works in more detail:
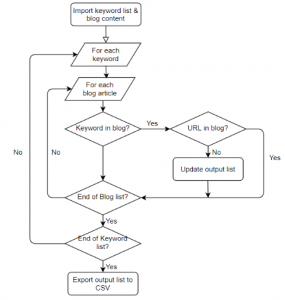
Basically the script gets a keyword from the list and checks every article to see if the keyword and target url is present. If the keyword is present, but target URL is not then the output file is updated with the article URL, target URL and keyword. The process is then repeated for every keyword. Eventually, a full list of blog URLs will be exported with the linking opportunities. This just leaves you with the small task of updating the links.
To run, just load the script, ensuring the CSVs are in the same folder. And hey presto! Your list of internal linking opportunities is complete!
[do_widget id=custom_html-3]
Issues
Speed
The main issue with this script is that FOR loops are quite inefficient. For larger sites, you could easily be looking at checking millions of combinations of article and keyword. Whilst this may only take a few minutes, it might make it hard to scale up for massive sites.
Red herrings
Not all instances of keywords will be internal linking opportunities. For example, a brand you want to link to might be mentioned within a product name. For that example, linking to the product would make far more sense and provide a better user experience.
For this reason, I strongly recommend against using an automated solution to update the internal links as some will be wrong.
Keyword formatting
Sometimes a keyword will contain an apostrophe, an accent or even a spelling mistake. When these are present, the script will not pick them up. I recommend paying close attention to your keyword list and ensuring that any variations are included.
Future versions
Since this method is slow to run on large websites, future versions of this script will run by merging tables instead of using FOR loops. This will make the script far more effiencient and enable crawling of massive sites in seconds.
I would also like to remove the reliance on Screaming Frog and scrape the article pages directly from the Python script.
I will keep you all posted as I progress on this.
Try it for yourself!
So to summarize:
- Install Python
- Scrape blog content with Screaming Frog
- Format Keyword list and blog content CSVs
- Run script!
To download the script, just click here and download internal-link-finder.zip! No coding experience is necessary, its all been done for you.
[do_widget id=custom_html-3]
Thanks DAVID GOSSAGE for your helpful script.
Thanks very much for sharing this awesome script.
I just came across your article via Twitter. I am also exploring Python for SEO and I must say you have done a commendable job here. Thanks for sharing this script. Bookmarked your blog for more useful Python scripts. Keep up the great work 🙂